Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
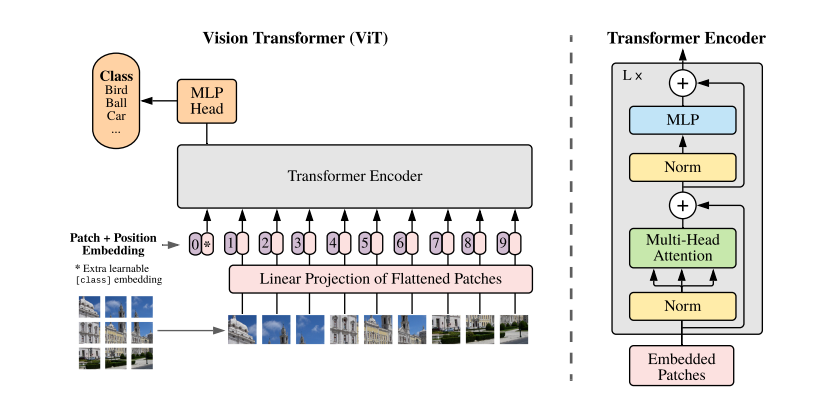
시각적 패턴을 인식하는 합성곱 신경망(CNN)은 컴퓨터비전의 de facto 표준으로 폭넓게 사용되지만,
데이터에서 의미론적 문맥(semantic context)을 유추하는 학습은 불가능하다.
반면에 NLP 분야에서 주목받던 Transformer 계열의 추론 성능은 비약적으로 상승했는데,
학습량이 일정 수준을 넘어서면 모델이 처음 보는 작업에서도 zero-shot 추론이 가능함을 보였다.
본 논문에서는 이미지 분류용 합성곱 레이어를 Transformer Encoder 로 대체한 새로운 유형의 모델을 제시하는데,
이는 CV 분야에서 고질적인 이슈로 지적되었던 일반화 성능 문제의 돌파구가 될 것으로 예상한다.
