Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
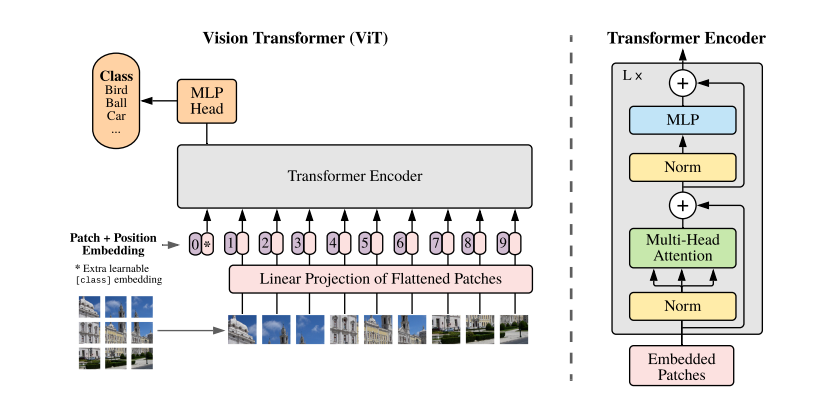
Transformer 모델은 토큰의 유사도를 비교하는 self-attention 구조의 유연성 덕분에 높은 수준의 task-agnostic performance 를 보여주었다. 또한 학습에 사용되는 데이터 규모가 일정 수준을 넘어서면 downstream task 에서도 일관된 성능을 보이는 zero-shot learning 현상이 감지되기도 한다. 본 논문의 저자들은 Patch embedding 기법을 고안해서 Transformer 인코더 구조에 어떠한 변형도 가하지 않고 비전 인식 분류 문제에 적용하는 기발한 아이디어를 제시한다.
