Vision Transformer
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
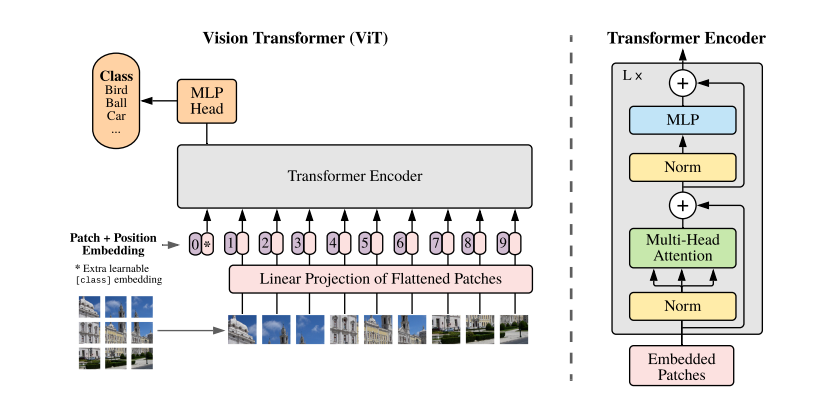
Transformer 모델은 토큰의 유사도를 비교하는 self-attention 구조의 유연성 덕분에 높은 수준의 task-agnostic performance 를 보여주었다. 또한 학습에 사용되는 데이터 규모가 일정 수준을 넘어서면 downstream task 에서도 일관된 성능을 보이는 zero-shot learning 현상이 감지되기도 한다. 본 논문의 저자들은 Patch embedding 기법을 고안해서 Transformer 인코더 구조에 어떠한 변형도 가하지 않고 비전 인식 분류 문제에 적용하는 기발한 아이디어를 제시한다.
Patch Embedding
이미지를 일정 크기의 패치(Patch) 조각으로 분할해서 Transformer 인코더의 입력 토큰으로 취급하는 기법이다.
알고리즘
- 2차원 이미지를 \(P \times P\) 해상도의 패치 \(N\)개로 분할하고 각각 D차원 벡터로 임베딩한다
- 위치 정보를 반영하는 Positional embedding 을 각각의 패치 벡터에 더한다
- [CLS] 토큰이 맨 앞에 추가된 패치 시퀀스를 조합해서 Encoder 입력으로 밀어넣는다
수식 모델
\[
\begin{aligned}
z_0 &= [x_{\text{class}}; x_p^1 E; x_p^2 E; ...; x_p^N E] + E_{\text{pos}}
\\
z' &= MSA(LN(z_{\ell - 1}) + z_{\ell - 1})
\\
z_{\ell} &= MLP(LN(z'_{\ell})) + z'_{\ell}
\\
y &= LN(z_L^0)
\\
\text{where }& E \in \mathbb{R}^{(P^2 \cdot C) \times D}, E_{\text{pos}} \in \mathbb{R}^{(N + 1) \times D}, \ell = 1 ... L
\end{aligned}
\]
Inductive Bias
- 귀납 편향
- 관측된 데이터를 일관되게 예측하려면 귀납적 추론으로 형성된 편향치가 요구된다
- 일반화 성능은 모델의 귀납 편향이 모집단을 얼마나 반영하는지 평가하는 지표이다
- 귀납 편향이 내제된 모델
- 합성곱 레이어의 국소성(spatial locality)
- 풀링 레이어의 이동불변성(translation invariance)
- 귀납 편향의 부재
- 저자는 소규모 데이터로 학습된 모델 성능이 저조한 이유를 귀납 편향의 부재로 설명한다
- ViT 구조는 CNN 과 다르게 공간적 편향이 내제되지 않아서 순수하게 데이터 분포만으로 학습한다
Performance
논문 결론에서 제시된 실험 결과표
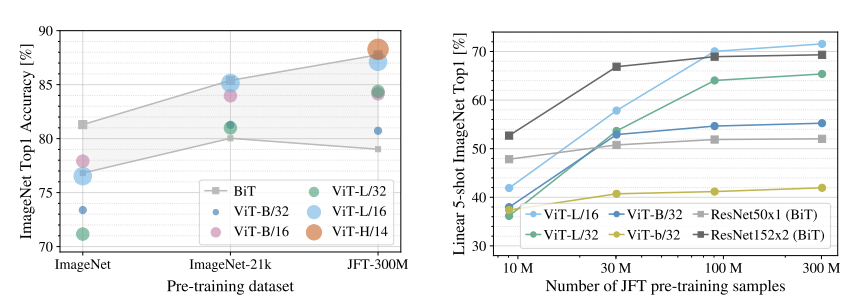
- ImageNet 130만 장을 학습한 ViT 모델은 ResNet (BiT) 보다 낮은 성능을 보인다
- JFT 이미지 3억 장을 학습한 ViT 모델은 ResNet 보다 높은 성능을 보인다
- LLM 분야에서 발견된 스케일링 법칙이 비전 인식에서도 관측될 수 있음을 보여주는 실험